

In a recent project, our team built an ETL platform for Data Migration. It was a Typescript project and the infrastructure was on AWS. The project also involved working with multiple teams who will be using our platform to spin up their pipelines to migrate their data. It included,
- 15+ teams working simultaneously
- 30+ assets (business entity) to be migrated
- 18+ pipelines actively running at once
- 80+ developers contributing to the codebase
- 5-10 production deployments on average in a day
- 2.7 billion+ events through the platform
In this article, we’ll focus on how Monorepo was used, the issues it solved, the problems we faced while using it and how they were tackled to make the whole project more effective and efficient.
Challenges in the project setup
Due to the scale of the project and time constraints, we faced a few problems upfront.
- The system had to allow for simultaneous development by all the teams involved, independently.
- The platform had to be highly scalable, available and replicable.
- The pipelines had to be able to run all at once and not affect each other.
- The teams had to have some flexibility while developing their pipelines as well.
- As the platform code was constantly updated, the teams had to be able to access the latest version at any time.
In order to cater to these requirements, as the platform team, we had followed certain strategies before and during development. We’ll look into some of them in the next section.
Monorepo in this project
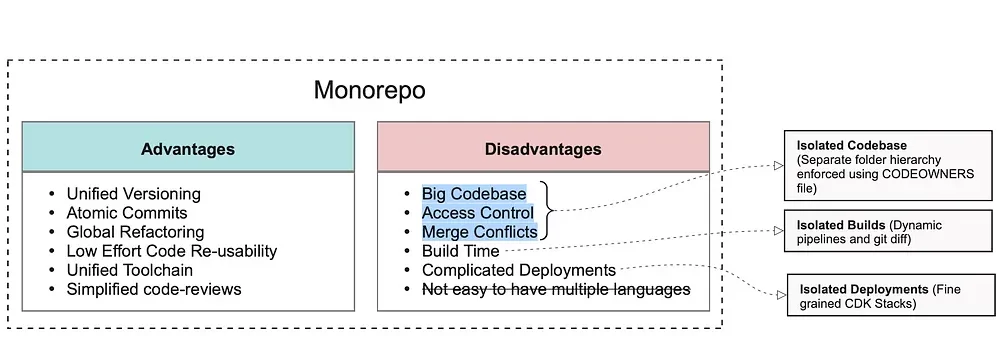
The pipeline infrastructure code was replicable and also had common modules. The teams will have to build their own pipeline with its set of infra components and also be able to access the common tools and libraries provided for ease of use.
There were two paths to take. The platform code and other tools could be packaged and provided as libraries which would lead to versioning issues, delay in availability of new features and compatibility issues. It also meant that the code would be in different repos making it difficult to maintain and could have a lot of redundant code. On the other hand, if a Monorepo was used, these libraries could be present in the same repository and can be cross-referenced by the various teams.
Using a Monorepo was one of the key decisions made at the start of the project and we followed a trunk based development. This implied that all the 15+ teams and the platform team will develop on the same repository.
By having the platform infra code along with the asset pipeline code, instead of as installable packages, we reduce wait time and versioning issues. The teams would get immediate access to new platform features.
Monorepo helped to reduce redundancy by extracting the common code and enabled maintainability and scalability of the large project codebase. Following a trunk based development enabled us to deploy the code in production without having to cross multiple hurdles. This way, the teams can test out their pipelines and verify if the data is flowing through end-to-end pretty quickly.
However, there were still more issues to be solved and using a Monorepo comes with its own set of challenges, which had to be navigated.
- Since all the code is in a single repository, we had to ensure that the teams don’t overwrite other teams’ code.
- In a project of this scale, the code base grows very fast and this means longer build and deployment times. It would be ideal to have independent build and deployment for each pipeline.
- With multiple teams working at once, it is essential to maintain order in the codebase. Defining contracts and structure in the system was necessary.
- It was also good to have a framework which the teams can use for the infrastructure setup, which enables them to focus solely on the business logic.
Strategies we used
Even though Monorepo brought all the code together, we still had to create a setup where the different teams could develop their pipelines at the same time. We followed a few strategies which aided in making the development experience smooth. Some of them are:
Let’s look deeper into each of these to see how they helped in the bigger picture.
Separation of concern
Using this strategy, we defined the structure of the repository. The platform infrastructure code and asset pipeline code was separated. Each team would have a separate package which contains their code. As the platform team, we were able to extract the common code out and make it available for all.
In order to prevent overwriting of other teams’ work, the CODEOWNERS file was used. In here, the individual teams were mapped to their modules and incase of any changes to it, they would be notified for approval.
One of the tools that helped in establishing this pattern even more strongly was the Yarn Package Manager. The Workspaces feature provided help in creating multiple workspaces within the same project. It links the various packages and simplifies cross-referencing.
This way, the individual pipeline or asset package can be used in its own workspace. This allows for flexibility within the individual module and independent development for the team. Using this we could also differentiate deployable modules and libraries, which comes in handy while creating Dynamic Pipelines.
One click away to deployment
Another key issue in the project was time. It was essential for the teams to be able to have a working pipeline as soon as possible. In order to solve this issue, as the platform team, we developed CLI tools and libraries which can fast track development. Using a monorepo came in handy to set this up.
The pipeline infrastructure and the basic skeleton code were created as replicable entities.
When a new team is onboarded, all that they would have to do is run a CLI command and in a few minutes have a working pipeline ready to be deployed.
This removed a lot of redundant code and established a common structure across teams. Additionally, developers could now focus only on the business logic of the migration rather than the platform set-up.
Sharing of common code
Having these two strategies in place opened up a lot of doors for the platform team to improve developer experience. To start with, we developed utilities for the teams to use during development. With the help of Typescript, some operations could be created as methods and all of this can be referenced from the asset packages.
This also led to the creation of a development framework, batch job framework, schedulers, monitoring features and other library tools. Instead of providing these as installable packages as it is usually done, by using a Monorepo, they could be separated as library modules and provided as references. Most of them were created to be opt-in features, thereby giving the teams some flexibility.
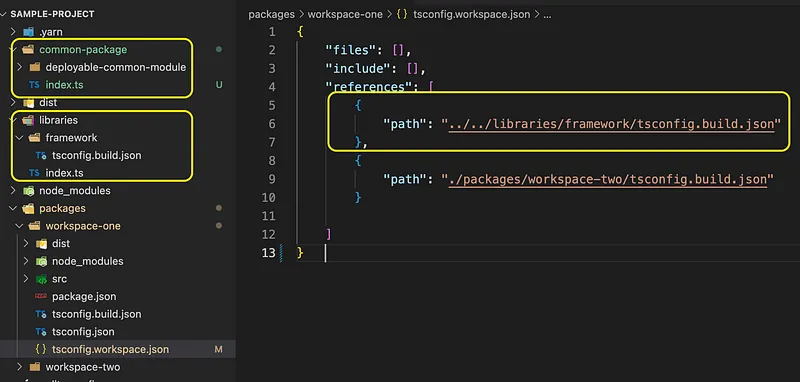
As shown above, common code can be added as deployable packages and as libraries, which can be cross-referenced by other modules in the project.
Dynamic Pipelines
While the code is being developed in different workspaces, with the size of the project, it would lead to long build and deployment times. At the same time, various teams could be in different stages of development and might not want to deploy their solution at that point in time.
To solve this problem of using a monorepo, Dynamic Pipelines were used. We needed to establish a few features.
- The pipeline(s) to be deployed should be configurable.
- New image to be published only if there are changes or use existing image.
- Differentiate deployment from feature, dev and prod branches.
The tool in use was Buildkite and it requires a configuration file — pipeline.yml — for creating a build pipeline. Since we already had separation in code using Yarn, we employed the use of workspace-tools library provided by Microsoft. This tools works in combination with package managers including yarn to provide utilities for monorepos.
Using this, we were able to configure generating Dynamic Pipelines. Teams had the option to provide the asset and branch name. Using these customisations and other existing data, pipelines will be generated dynamically using Typescript, which can then be plugged into to the json config of Buildkite.
This helped in
- creating build/deploy pipelines for the required assets
- apply the respective configurations based on environment
- allow for teams to work independently of each other.
Other helpful strategies
- While developing the common code, we provided opinionated implementation, but also had the option the replace the whole thing if the teams desired. Additionally, hooks were provided to customise parts of the implementation as well.
- Using Typescript in the project helped in establishing structure throughout. This enabled the team to develop common reusable app code as well, like batch job frameworks, which might have been harder otherwise.
- By making most of the features as plug-and-play, provided more flexibility to teams using the development framework. Additionally, it also enabled teams who did not use this framework, to plug in the features they needed.
Given any development tool or practise, it comes with its advantages and disadvantages. We learnt from this project that by using the right combination of strategies and technologies, a tool like Monorepo can be used for a large Data Migration Platform effectively and efficiently.

